Arjun Majumdar
Research Scientist | FAIR RoboticsAbout
I was recently a Research Scientist at Meta on the FAIR Robotics team.
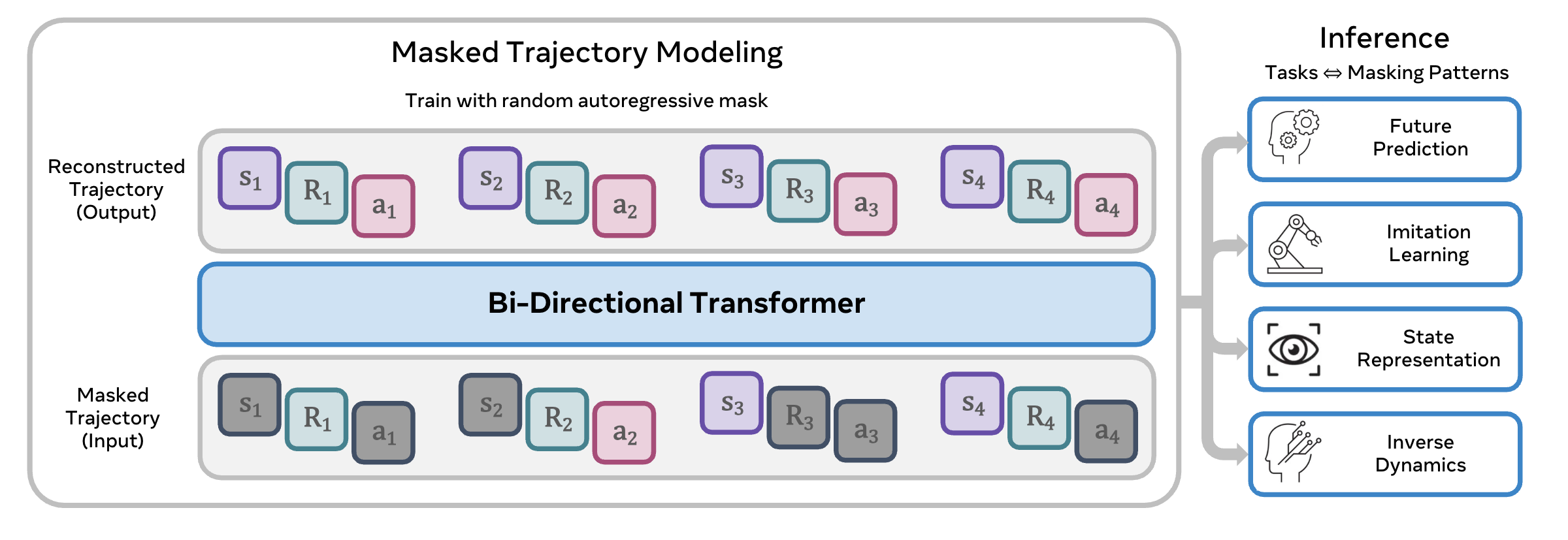
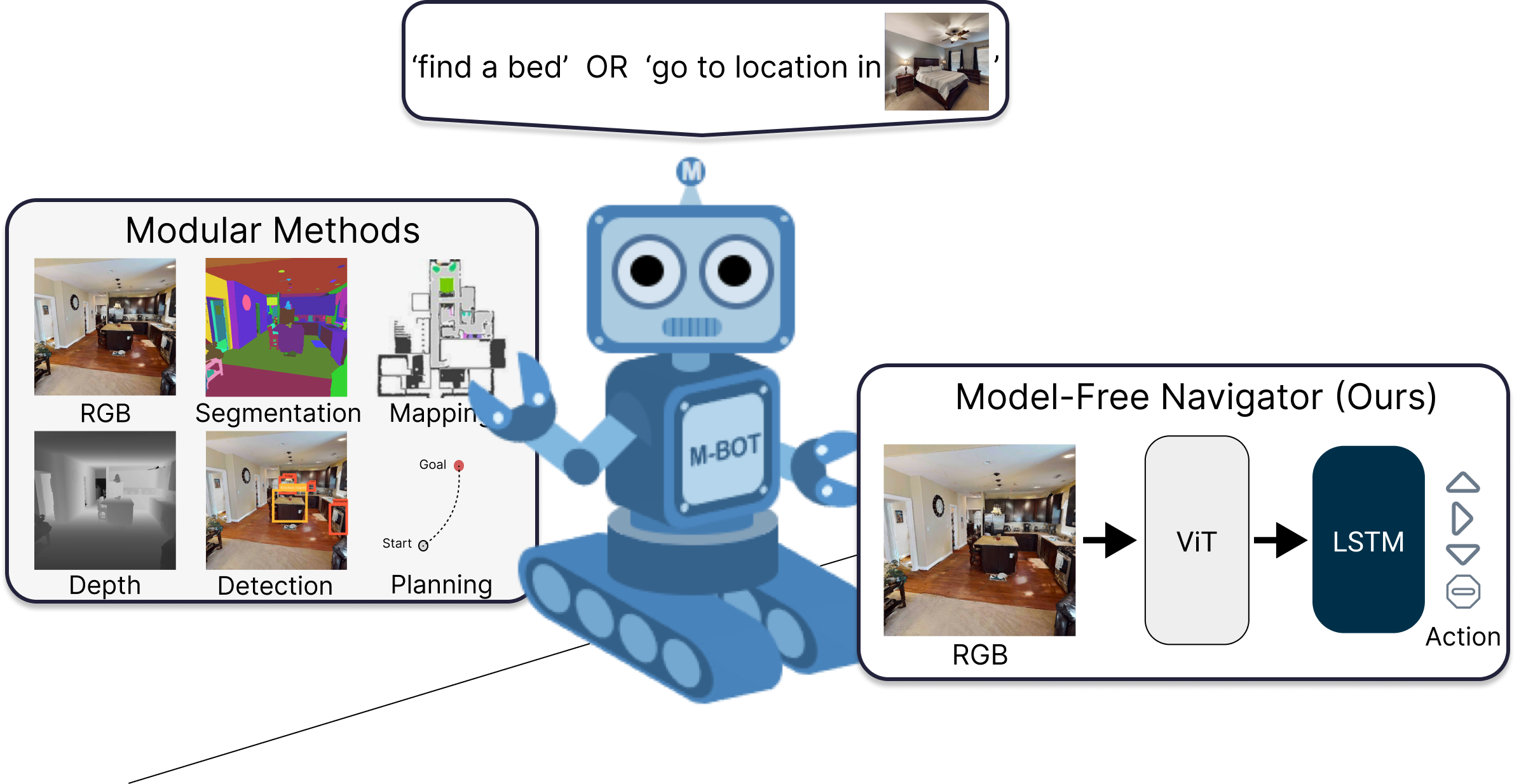
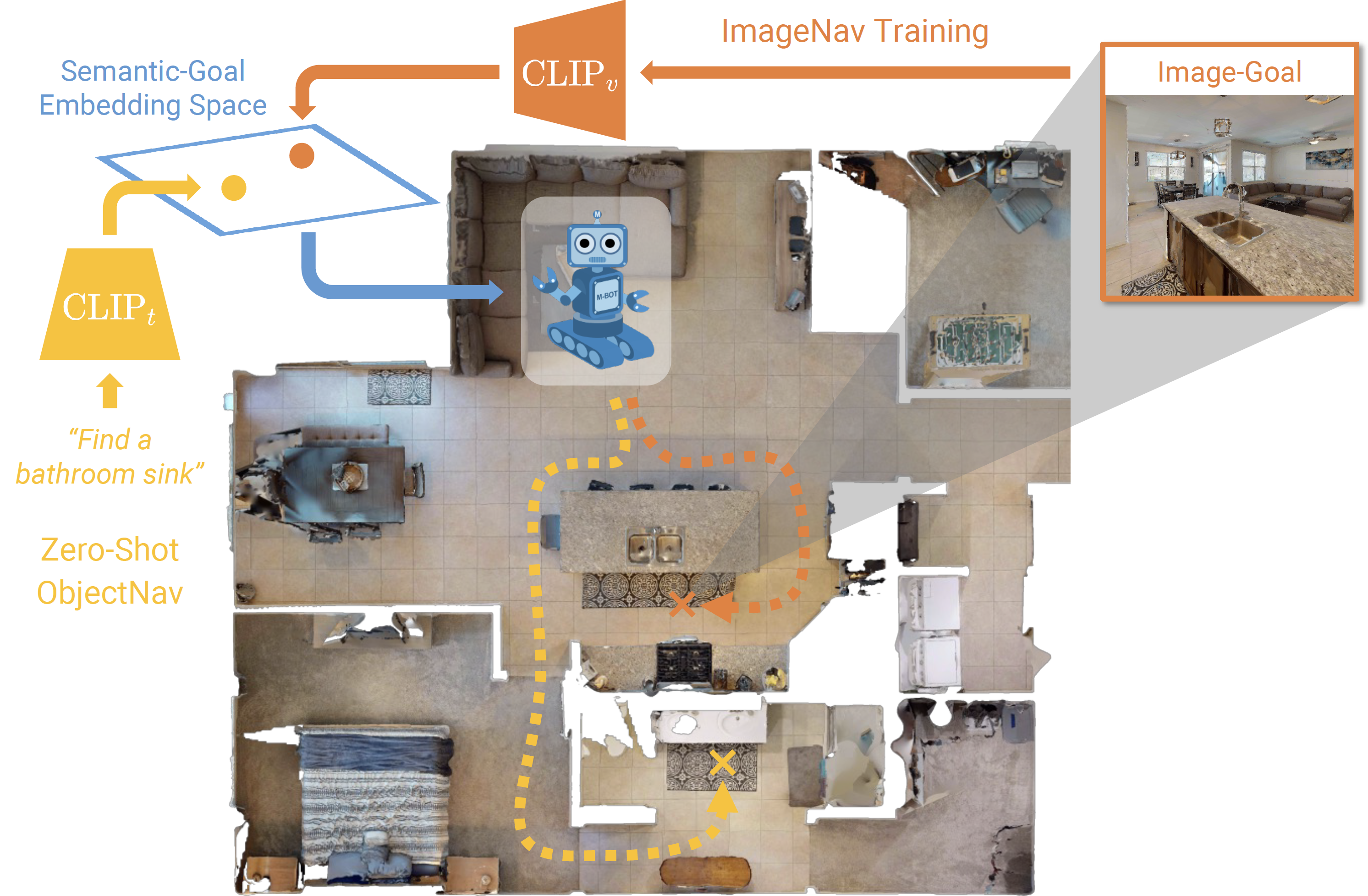
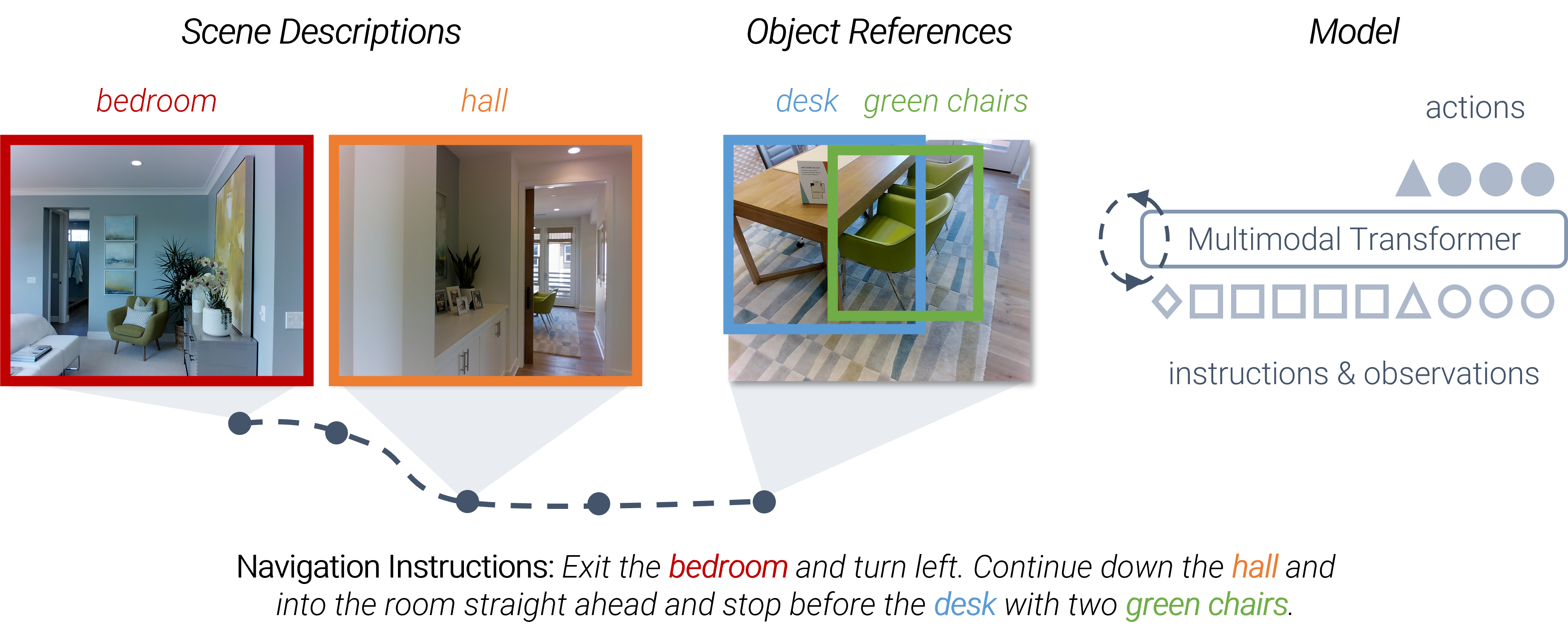
The long-term goal of my work is to develop generalist robots that can accomplish a wide variety of tasks in diverse environments. My recent work has focused on scaling robot learning through world modeling.
I was previously a PhD Student at Georgia Tech, where I was advised by Dhruv Batra. During my PhD, I interned at Meta AI in 2023 and 2024 with Franziska Meier and Aravind Rajeswaran. In the summer of 2022, I was a student researcher with the perception and robotics teams at Google AI working with Leo Guibas and Fei Xia. In the summer of 2021, I interned at Amazon AI where I worked with Jesse Thomason and Gaurav Sukhatme. In the summer of 2020, I was an intern at FAIR working with Ross Girshick.
Prior to my PhD, I was a researcher at MIT Lincoln Laboratory where my work focused on problems such as visual question answering, image segmentation, and image-to-image translation.
email | google scholar | github | cv